Thiết kế kiến trúc MLOps
AWS MLOps Retail Prediction Platform
AWS MLOps Retail Prediction là một hệ thống MLOps end-to-end hoàn chỉnh được xây dựng trên AWS Cloud, tự động hóa toàn bộ quy trình từ xây dựng hạ tầng, huấn luyện mô hình, triển khai inference API, đến giám sát và tối ưu chi phí. Dự án được thiết kế để đảm bảo tính mở rộng, độ tin cậy và bảo mật cao cho các ứng dụng Machine Learning trong thực tế.
1. Kiến trúc MLOps trên AWS Cloud
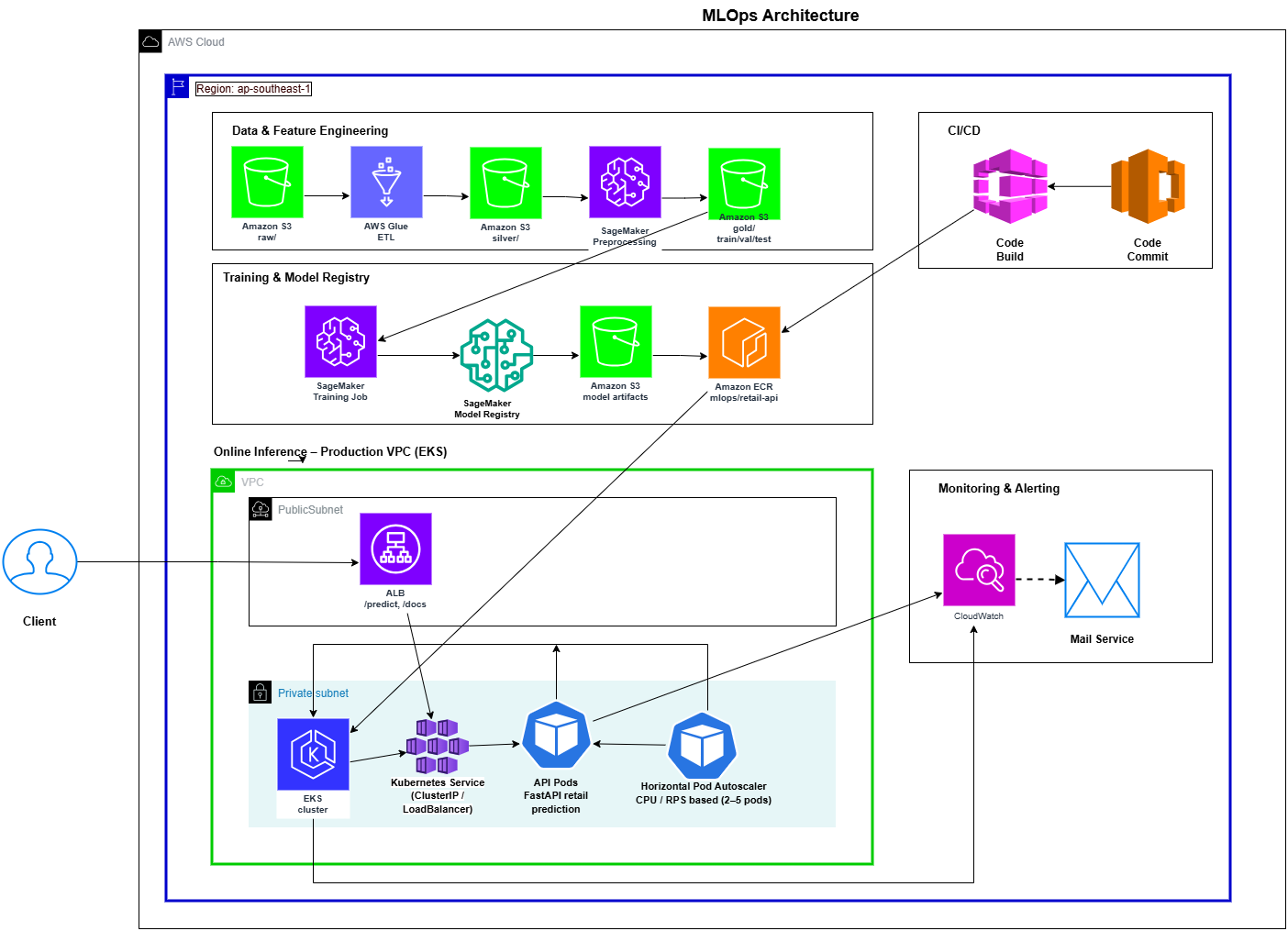
1.1 Mục tiêu dự án
Tự động hóa hoàn toàn quy trình MLOps:
- 🏗️ Infrastructure as Code: Xây dựng hạ tầng tự động bằng Terraform (VPC, EKS, IAM, EC2, ECR, S3)
- 🤖 ML Training: Huấn luyện mô hình phân tán trên SageMaker với model registry
- 🚀 Container Deployment: Đóng gói & triển khai inference API trên EKS với autoscaling
- 📊 Monitoring & Security: Giám sát bằng CloudWatch, bảo mật bằng KMS & CloudTrail
- 🔄 CI/CD Pipeline: Pipeline tự động từ thay đổi code/data → build → train → deploy
- 💰 Cost Optimization: Tích hợp DataOps và teardown để tối ưu chi phí
1.2 Flow tổng quát
Infrastructure → Training → Deployment → Monitoring → CI/CD → Cost Optimization
2. Bài toán dự đoán độ nhạy giá khách hàng
2.1 Mô tả dataset - dunnhumby Source Files
Nguồn dữ liệu: dunnhumby Source Files
Tập dữ liệu sử dụng: transaction.csv (≈ 2.67 triệu dòng, 22 cột)
Mô tả: Mỗi dòng dữ liệu đại diện cho một sản phẩm trong một lần mua hàng của khách hàng.
2.1.1 Cấu trúc dữ liệu chi tiết
| Tên cột | Kiểu dữ liệu | Mô tả / Ý nghĩa | Ví dụ giá trị |
|---|---|---|---|
SHOP_WEEK |
int64 |
Tuần mua hàng (theo định dạng YYYYWW) | 200807 |
SHOP_DATE |
int64 |
Ngày mua hàng (định dạng YYYYMMDD) | 20080407 |
SHOP_WEEKDAY |
int64 |
Thứ trong tuần (1=Chủ nhật, 2=Thứ hai, …, 7=Thứ bảy) | 2 |
SHOP_HOUR |
int64 |
Giờ giao dịch (0–23) | 14 |
QUANTITY |
int64 |
Số lượng sản phẩm mua trong dòng giao dịch | 1 |
SPEND |
float64 |
Số tiền chi tiêu (đơn vị: bảng Anh £) cho dòng giao dịch (sản phẩm × số lượng) | 1.01 |
PROD_CODE |
object |
Mã sản phẩm chi tiết (cấp thấp nhất) | PRD0900005 |
PROD_CODE_10 |
object |
Mã nhóm sản phẩm cấp 1 (chuyên mục chính) | CL00155 |
PROD_CODE_20 |
object |
Mã nhóm sản phẩm cấp 2 | DEP00053 |
PROD_CODE_30 |
object |
Mã nhóm sản phẩm cấp 3 | G00016 |
PROD_CODE_40 |
object |
Mã nhóm sản phẩm cấp 4 (có thể mô tả danh mục con) | NaN / G00420 |
CUST_CODE |
object |
Mã định danh khách hàng (ẩn danh) | CUST0000123 |
seg_1 |
object |
Nhóm phân khúc khách hàng cấp 1 (phân loại hành vi tổng quan) | BG / AZ / NaN |
seg_2 |
object |
Nhóm phân khúc khách hàng cấp 2 (chi tiết hơn seg_1) |
DI / CZ / BU |
BASKET_ID |
int64 |
Mã định danh giỏ hàng (mỗi lần mua của khách) | 994110500233340 |
BASKET_SIZE |
object |
Kích thước giỏ hàng (Small/Medium/Large) | S / M / L |
BASKET_PRICE_SENSITIVITY |
object |
Mức độ nhạy cảm với giá của khách hàng trong giao dịch (Low/Medium/High hoặc mã viết tắt như LA, MM, UM) | MM / LA / UM |
BASKET_TYPE |
object |
Loại giỏ hàng (Full Shop / Small Shop / Top Up / Fresh / Nonfood…) | Full Shop |
BASKET_DOMINANT_MISSION |
object |
Mục đích chính của giỏ hàng (Mixed, Grocery, Fresh, Nonfood, …), thể hiện loại sản phẩm chủ yếu | Mixed / Fresh |
STORE_CODE |
object |
Mã cửa hàng nơi giao dịch diễn ra | STORE00001 |
STORE_FORMAT |
object |
Định dạng cửa hàng (LS = Large Store, SS = Small Store, Express, v.v.) | LS |
STORE_REGION |
object |
Khu vực địa lý của cửa hàng (E01–E05, tương ứng các vùng tại Anh quốc) | E02 |
2.1.2 Nhóm features theo nghiệp vụ
| Nhóm | Cột | Ý nghĩa |
|---|---|---|
| 🛒 Giỏ hàng | BASKET_SIZE, BASKET_TYPE, BASKET_DOMINANT_MISSION |
Kích cỡ, loại và mục đích giỏ hàng |
| 💸 Chi tiêu | SPEND, QUANTITY |
Số tiền và số lượng mua |
| 🏬 Cửa hàng | STORE_REGION, STORE_FORMAT |
Khu vực và loại cửa hàng |
| 📦 Sản phẩm | PROD_CODE_20, PROD_CODE_30 |
Nhóm sản phẩm chính |
| 🎯 Nhãn | BASKET_PRICE_SENSITIVITY |
Độ nhạy giá – Low / Medium / High |
2.2 Mục tiêu bài toán
Xây dựng mô hình machine learning phân loại đa lớp (multi-class) để dự đoán mức độ nhạy giá (Low / Medium / High) của khách hàng trong mỗi giao dịch, dựa trên đặc trưng của giỏ hàng, cửa hàng và hành vi mua sắm.
💡 Ứng dụng: Phân nhóm khách hàng theo độ nhạy giá → định giá linh hoạt, cá nhân hoá khuyến mãi và tối ưu doanh thu.
2.3 Loại bài toán và mô hình
Loại: Phân loại đa lớp (Supervised Learning)
Mô hình dự kiến:
| Mô hình | Lý do |
|---|---|
| Decision Tree | Dễ giải thích feature impact |
| Random Forest | Độ chính xác cao, giảm overfitting |
| Logistic Regression (multi-class) | Baseline so sánh |
| XGBoost | Hiệu quả với tabular data |
Đánh giá: Accuracy, Precision, Recall, F1-score, Confusion Matrix
2.4 Kiến trúc tổng thể (AWS MLOps)
Luồng xử lý:
Dữ liệu gốc (CSV)
→ S3 raw zone
→ ETL (Glue/EKS Job)
→ S3 silver/gold zone
→ SageMaker Feature Store
→ Training (SageMaker Training Job)
→ Model Registry
→ Deployment (EKS FastAPI + ALB)
→ CloudWatch Monitoring
Thành phần chính:
- Amazon S3: Lưu raw/silver/gold dataset, partition theo
STORE_REGION,BASKET_TYPE - Glue/Athena: ETL và khám phá dữ liệu
- SageMaker Feature Store: Quản lý feature parity train ↔ inference
- SageMaker Training & Model Registry: Huấn luyện và phiên bản mô hình
- EKS (FastAPI): Triển khai API real-time dự đoán độ nhạy giá
- CloudWatch: Theo dõi độ trễ, accuracy thực tế, chi phí
2.5 KPI và kết quả kỳ vọng
| Nhóm | Chỉ số | Mục tiêu |
|---|---|---|
| ML | Accuracy | ≥ 0.75 |
| ML | Macro F1 | ≥ 0.70 |
| ML | Precision (per class) | ≥ 0.65 |
| Ops | P95 latency (API) | < 200 ms |
| Ops | Throughput (requests/s) | ≥ 100 |
| Business | Giảm sai sót định giá | ≥ 10% |
| Cost | Infrastructure cost/month | < $500 |
3. Project Structure
Dự án được tổ chức theo cấu trúc modularity với separation of concerns rõ ràng:
retail-forecast/
├── README.md # Project overview & setup guide
├── .gitignore # Git ignore patterns
├── aws/ # AWS-specific configurations
│ ├── .travis.yml # Travis CI configuration
│ ├── Jenkinsfile # Jenkins pipeline configuration
│ ├── infra/ # Terraform infrastructure
│ │ ├── main.tf # Main infrastructure config
│ │ ├── variables.tf # Input variables
│ │ └── output.tf # Output values
│ ├── k8s/ # Kubernetes manifests
│ │ ├── deployment.yaml # Application deployment
│ │ ├── service.yaml # Service configuration
│ │ ├── hpa.yaml # Horizontal Pod Autoscaler
│ │ └── namespace.yaml # Namespace definition
│ └── script/ # Automation scripts
│ ├── create_training_job.py # SageMaker training job
│ ├── register_model.py # Model registry script
│ ├── deploy_endpoint.py # Model deployment
│ └── autoscaling_endpoint.py # Auto-scaling setup
├── azure/ # Azure-specific configurations
│ ├── azure-pipelines.yml # Azure DevOps pipeline
│ ├── aml/ # Azure ML configurations
│ │ ├── train-job.yml # Training job definition
│ │ ├── train.Dockerfile # Training container
│ │ └── infer.Dockerfile # Inference container
│ ├── infra/ # Bicep infrastructure
│ │ └── main.bicep # Azure infrastructure
│ └── k8s/ # AKS manifests
│ ├── deployment.yaml # Application deployment
│ ├── service.yaml # Service configuration
│ └── hpa.yaml # Horizontal Pod Autoscaler
├── core/ # Shared ML core modules
│ └── requirements.txt # Core Python dependencies
├── server/ # Inference API server
│ ├── DockerFile # Container definition
│ ├── requirements.txt # Server dependencies
│ └── Readme.md # Server documentation
└── tests/ # Test suites
└── (test files) # Unit & integration tests
3.1 Cấu trúc thư mục chi tiết
📂 aws/ - AWS Implementation
infra/: Terraform Infrastructure as Codek8s/: Kubernetes manifests cho EKS deploymentscript/: Python scripts cho SageMaker automation- CI/CD configurations (Jenkins, Travis)
📂 azure/ - Azure Implementation
infra/: Bicep templates cho Azure resourcesaml/: Azure ML configurationsk8s/: AKS manifests- Azure DevOps pipeline
📂 core/ - Shared Components
- Common ML utilities và libraries
- Shared dependencies và configurations
📂 server/ - Inference API
- FastAPI application
- Docker containerization
- API documentation
📂 tests/ - Testing Framework
- Unit tests cho ML pipeline
- Integration tests cho infrastructure
- End-to-end testing scenarios
4. Công nghệ sử dụng
4.1 Infrastructure & Platform Stack
- Infrastructure as Code: Terraform cho automated provisioning
- Container Platform: Amazon EKS (Kubernetes) với managed node groups
- Container Registry: Amazon ECR với vulnerability scanning
- Networking: VPC multi-AZ, NAT gateways, security groups
- Load Balancing: Application Load Balancer với health checks
4.2 ML & Data Platform Stack
- ML Training: Amazon SageMaker với distributed training
- Data Storage: Amazon S3 data lake với versioning
- Model Registry: SageMaker Model Registry cho version control
- Data Processing: Automated preprocessing và feature engineering
- ML Framework: TensorFlow/PyTorch trên SageMaker training jobs
4.3 DevOps & Security Stack
- CI/CD Platform: Jenkins hoặc Travis CI cho automated pipelines
- Monitoring: CloudWatch (logs, metrics, dashboards, alarms)
- Security: KMS encryption, CloudTrail audit, IAM với IRSA
- DataOps: S3-based data versioning và lifecycle management
5. Kiến trúc MLOps chi tiết
5.1 Phase 1: Infrastructure Foundation
Terraform Infrastructure as Code
- VPC với multi-AZ public/private subnets
- EKS cluster với managed node groups (auto-scaling)
- IAM roles với IRSA (IAM Roles for Service Accounts)
- Security groups với least privilege access
- ECR repositories cho container images
Network Architecture
- Public subnets: NAT Gateway, Load Balancer
- Private subnets: EKS worker nodes, SageMaker
- VPC endpoints: S3, ECR, CloudWatch (giảm data transfer cost)
5.2 Phase 2: ML Training & Model Management
SageMaker Training Pipeline
- Data Ingestion: S3 data lake với automated validation
- Distributed Training: SageMaker training jobs với spot instances
- Model Registry: Versioned model artifacts với metadata tracking
- Experiment Tracking: Performance metrics và hyperparameter tuning
Data Management Strategy
- Raw data → Processed data → Feature store → Model artifacts
- S3 intelligent tiering cho cost optimization
- Data lineage tracking và version control
5.3 Phase 3: Containerized Inference Platform
EKS Deployment Architecture
- Docker Containers: FastAPI inference service
- Kubernetes Deployment: Rolling updates với zero downtime
- Horizontal Pod Autoscaler: Dynamic scaling dựa trên CPU/memory
- Service Discovery: Internal service communication
- Application Load Balancer: External access với SSL termination
Monitoring & Observability
- CloudWatch Logs: Centralized logging từ tất cả components
- Custom Metrics: Model performance, latency, throughput
- Alarms & Notifications: Automated alerting khi có issues
- Dashboards: Real-time visualization của system health
5.4 Phase 4: CI/CD & Automation
Automated Pipeline Flow
1. Code/Data Change → Git Webhook
2. Jenkins/Travis Build → Run Tests
3. SageMaker Training → Model Validation
4. Docker Build → Push to ECR
5. Kubernetes Deploy → Rolling Update
6. Health Check → Monitor Performance
DataOps Workflow
- Data Versioning: S3 với metadata tracking
- Data Quality: Automated validation và testing
- Feature Engineering: Reproducible pipelines
- Model Deployment: A/B testing capabilities
6. Scope & Expected Outcomes
6.1 In Scope
✅ Complete Infrastructure: Terraform IaC cho toàn bộ AWS resources
✅ ML Training: SageMaker distributed training với hyperparameter tuning
✅ Container Deployment: EKS với autoscaling và load balancing
✅ Security Best Practices: KMS encryption, CloudTrail audit, IAM least privilege
✅ Monitoring & Alerting: CloudWatch comprehensive monitoring
✅ CI/CD Automation: End-to-end pipeline từ code đến production
✅ Cost Optimization: Auto-scaling, spot instances, lifecycle policies
6.2 Out of Scope
❌ Multi-region deployment (focus on ap-southeast-1)
❌ Advanced ML features (A/B testing, canary deployments)
❌ Real-time streaming inference (batch-focused)
❌ Custom monitoring solutions (CloudWatch-only)
6.3 Expected Outcomes
🎯 Production-Ready MLOps Platform: Scalable, reliable, cost-effective
🎯 Automated ML Lifecycle: Từ data ingestion đến model deployment
🎯 Infrastructure Reproducibility: Terraform state management
🎯 Operational Excellence: Comprehensive monitoring và alerting
🎯 Cost Efficiency: Optimized resource usage với auto-scaling
Kiến trúc này được thiết kế để support enterprise-grade ML workloads với khả năng scale từ proof-of-concept đến production với hàng triệu requests/day.
Prerequisites: AWS account với permissions cho EKS, SageMaker, ECR, S3, CloudWatch, IAM. Terraform >= 1.0, kubectl, AWS CLI, Docker, Python 3.8+.