Data Pipeline Optimization
🎯 Mục tiêu Task 3
Tạo S3 bucket và tổ chức dữ liệu cho pipeline MLOps theo chuẩn raw → silver → gold → artifacts, chuyển đổi CSV → Parquet bằng AWS Glue Studio (Visual ETL) và đo benchmark hiệu năng đọc/ghi:
- Đo trên AWS CloudShell (đọc trực tiếp từ S3).
- Đo trên máy local (Windows, 16GB RAM).
Tập trung vào:
- Hiệu năng đọc/ghi: CSV vs Parquet.
- Dung lượng lưu trữ: trước/sau khi nén.
- Cách làm: từng bước cụ thể, có thể tái hiện.
💡 Task 3 – S3 Storage Optimization
- ✅ Tối ưu format: Parquet + Snappy thay vì CSV thuần.
- ✅ Tối ưu hiệu năng đọc/ghi cho ETL & training.
- ✅ Tối ưu dung lượng lưu trữ (giảm đáng kể GB).
- ✅ Bổ sung benchmark thực tế: CloudShell + local.
📥 Input từ Task 2: IAM Roles & Audit — account ID, IAM roles/policies and CloudTrail/audit setup required to create buckets, Glue roles and permissions.
🔧 Môi trường lab thực tế
- Account ID:
842676018087 - Region lab:
us-east-1 - Bucket:
mlops-retail-prediction-dev-842676018087
Dataset chính:
raw/transactions.csv
≈ 4,593.65 MB, 33,850,823 dòng- Ví dụ 1 file Parquet sau ETL:
silver/shop_week=200607/run-1761638745394-part-block-0-0-r-00000-snappy.parquet
≈ 458.45 MB, 33,850,823 dòng
1. Cấu trúc & tổ chức S3 bucket
1.1. Cấu trúc lưu trữ tổng quát
Áp dụng cho mọi account, dùng {account-id} làm placeholder:
s3://mlops-retail-prediction-dev-{account-id}/
├── raw/ # dữ liệu CSV gốc, immutable
├── silver/ # dữ liệu Parquet đã làm sạch / chuẩn hóa
├── gold/ # features, aggregated datasets cho training/serving
└── artifacts/ # model, metadata, logs, reports
Ý nghĩa:
- raw/: chỉ append, không sửa/xóa → phục vụ audit & reprocessing.
- silver/: nơi lưu Parquet tối ưu (schema chuẩn, sạch).
- gold/: dataset cuối cùng cho training/inference.
- artifacts/: model.tar.gz, notebook export, log, benchmark CSV,…
1.2. Cấu trúc thực tế trong lab
Với account ID của bạn:
S3 Bucket: mlops-retail-prediction-dev-842676018087
├── raw/
│ └── transactions.csv # file gốc ~4.59GB
├── silver/
│ ├── transactions/ # output từ Glue ETL (nếu không partition theo week)
│ └── shop_week=200607/
│ └── run-1761638745394-part-block-0-0-r-00000-snappy.parquet # ~458MB
├── gold/
│ └── (dành cho feature store / aggregated tables)
└── artifacts/
└── (lưu wyniki benchmark, model, logs,…)
Bạn có thể mở S3 Console để xác nhận đúng đường dẫn, nhất là:
raw/transactions.csv- Một file Parquet tiêu biểu trong
silver/shop_week=.../.
2. Tạo bucket & thư mục trên AWS Console
2.1. Tạo S3 Bucket
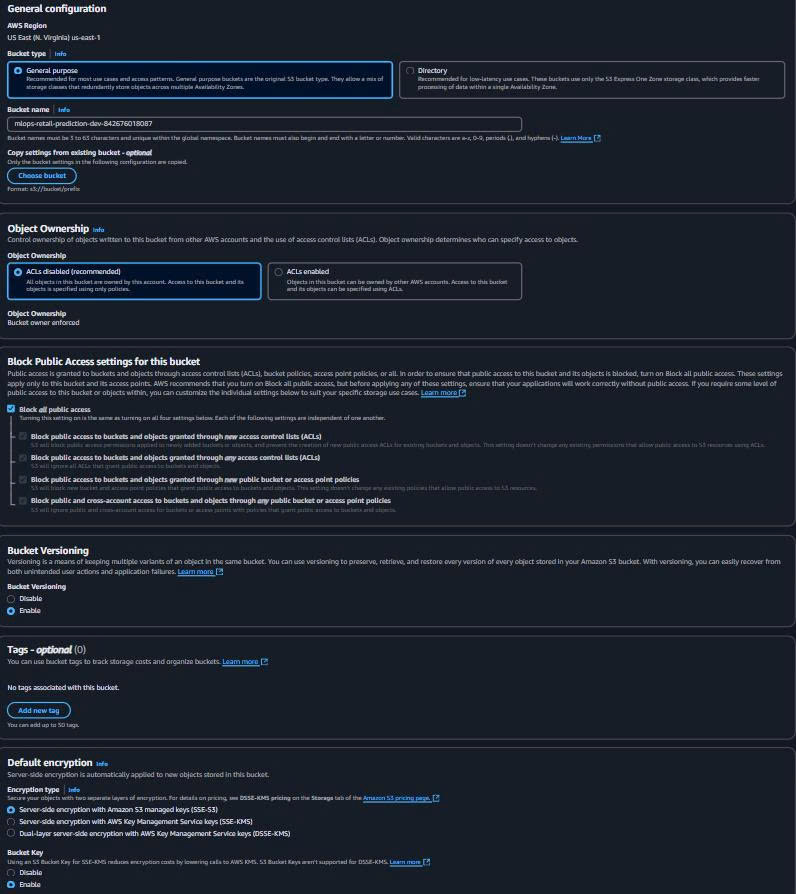
- Vào AWS Console → S3 → Create bucket.
- Cấu hình:
Bucket name: mlops-retail-prediction-dev-842676018087
Region: us-east-1
Block all public access: ✅ Enabled
Versioning: (khuyến nghị) Enabled
Default encryption: ✅ SSE-S3
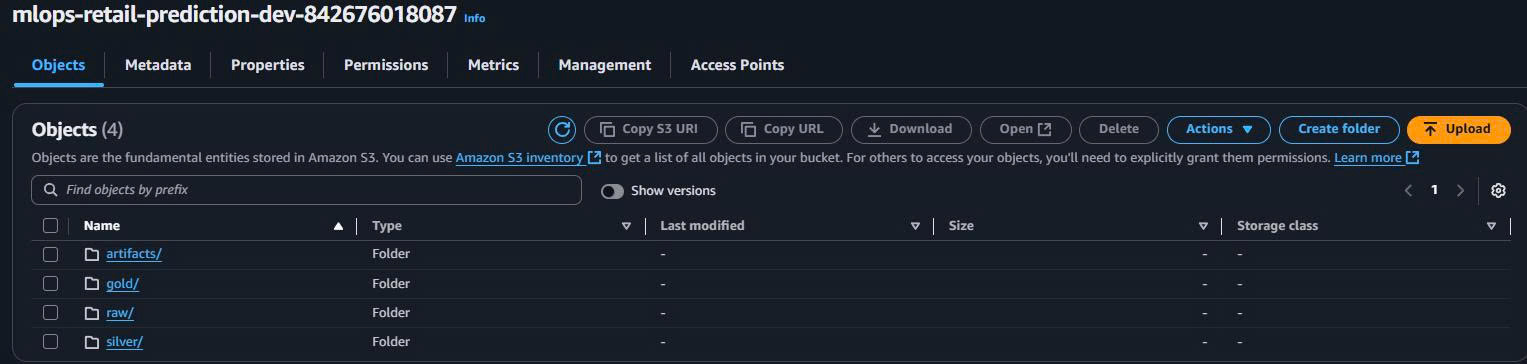
2.2. Tạo 4 thư mục chính
Trong S3 Console:
- Mở bucket
mlops-retail-prediction-dev-842676018087. - Create folder lần lượt:
raw/
silver/
gold/
artifacts/
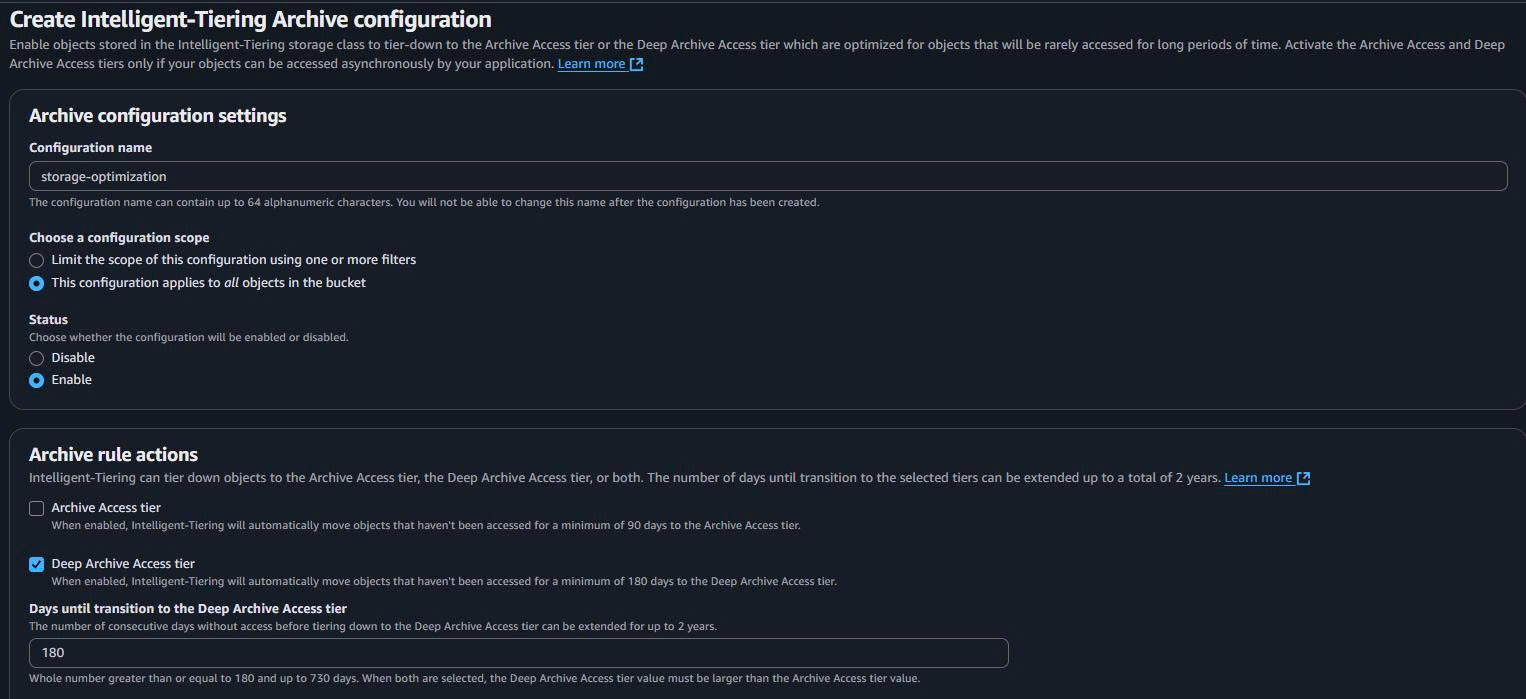
3. Bật Intelligent-Tiering (tối ưu chi phí)
Mục đích: dữ liệu ít truy cập (ví dụ raw/ cũ, artifacts/ log cũ) được chuyển tự động sang lớp lưu trữ rẻ hơn, không đổi URL.
Các bước:
- Vào bucket → tab Properties.
- Tìm phần Intelligent-Tiering archive configurations → Edit.
- Thêm cấu hình:
Configuration name: storage-optimization
Status: Enabled
Scope: Entire bucket (hoặc prefix cụ thể: raw/, silver/, gold/, artifacts/)
4. Chuyển CSV → Parquet bằng AWS Glue Studio (Visual ETL)
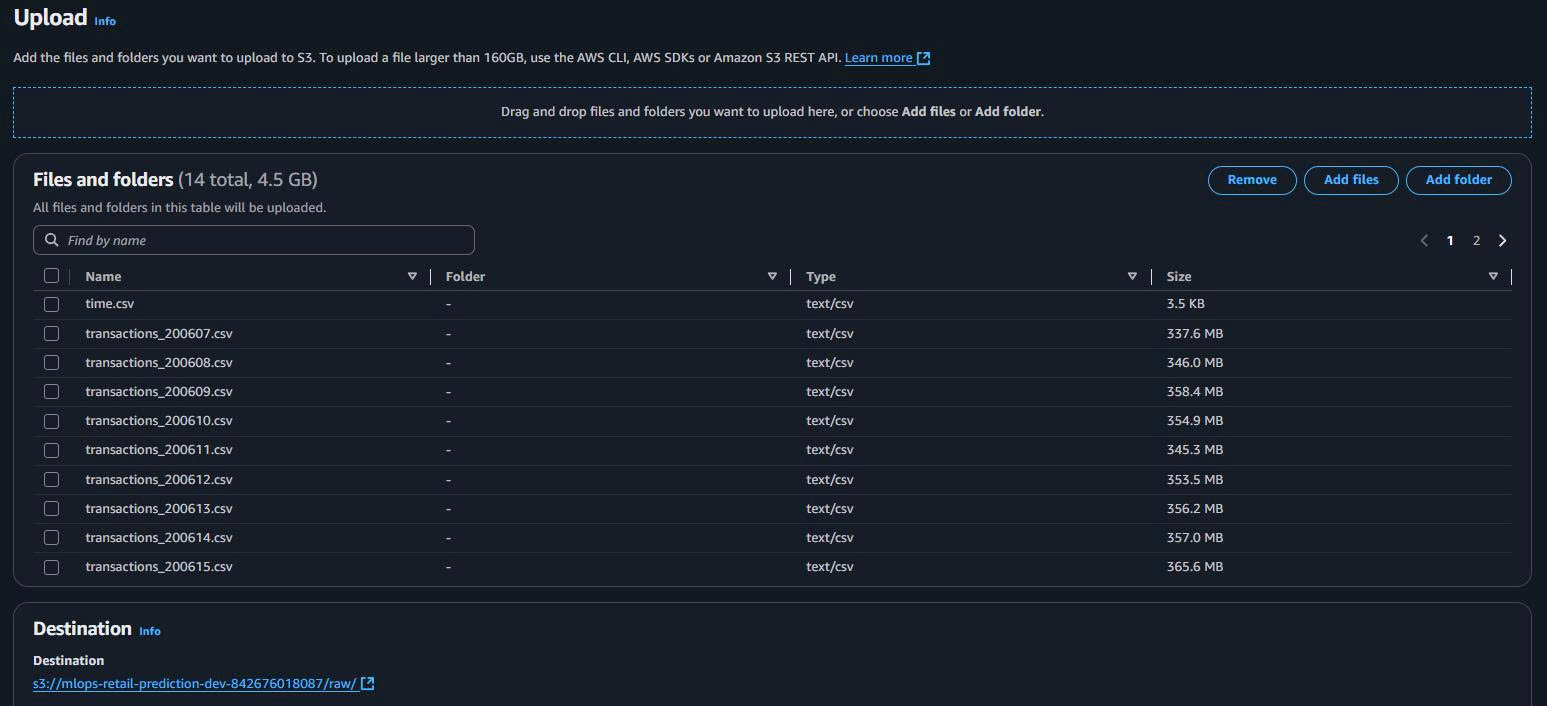
4.1. Upload transactions.csv vào raw/
Trên S3 Console:
- Mở bucket → folder
raw/. - Upload → Add files → chọn file
transactions.csvtrên máy. - Upload.
4.2. Tạo Glue Job (Visual ETL)
- Vào AWS Glue Studio → Jobs → Create job → Visual with a blank canvas.
- Đặt tên:
Job name: csv-to-parquet-converter
- Chọn/ tạo IAM Role có quyền:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": ["s3:GetObject", "s3:PutObject"],
"Resource": [
"arn:aws:s3:::mlops-retail-prediction-dev-842676018087/raw/*",
"arn:aws:s3:::mlops-retail-prediction-dev-842676018087/silver/*"
]
},
{
"Effect": "Allow",
"Action": [
"glue:*",
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents"
],
"Resource": "*"
}
]
}
4.3. Source node – đọc CSV từ S3
Trong canvas Glue Studio:
- Thêm S3 Source.
- Cấu hình:
Data source: S3
Format: CSV
S3 URL: s3://mlops-retail-prediction-dev-842676018087/raw/transactions.csv
First row as header: Enabled
Delimiter: ,
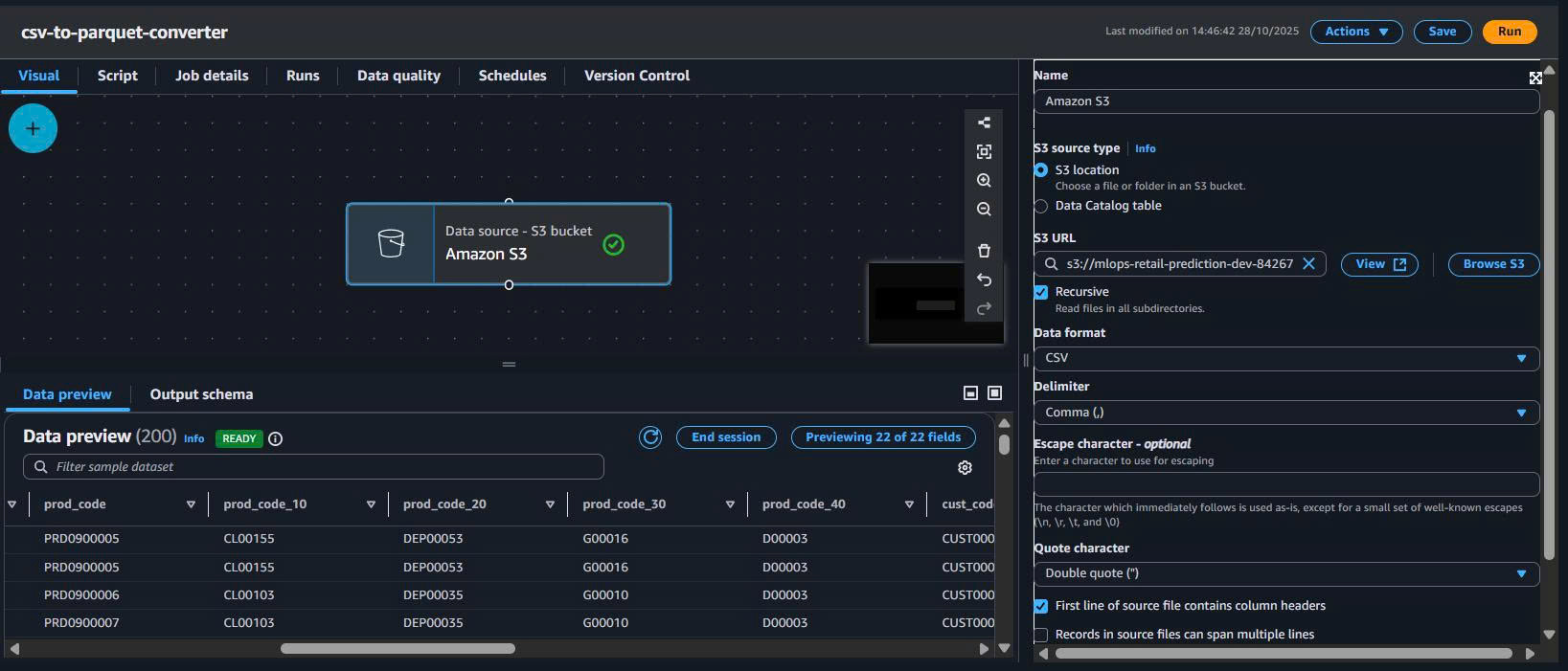
Tóm tắt:
| Field | Value |
|---|---|
| S3 bucket | mlops-retail-prediction-dev-842676018087 |
| Path | raw/transactions.csv |
| Format | CSV |
| Header | Yes |
| Delimiter | , |
4.4. Transform – ApplyMapping (tối ưu schema)
- Thêm node ApplyMapping.
- Kết nối Source → ApplyMapping.
- Mapping kiểu dữ liệu (ví dụ):
| Column | Source type | Target type | Ghi chú |
|---|---|---|---|
| SHOP_WEEK | long | int | int32 là đủ |
| SHOP_HOUR | long | tinyint | 0–23 |
| QUANTITY | long | smallint | Số lượng |
| STORE_CODE | string | string | Giữ nguyên |
| SPEND | decimal | decimal(10,2) | Tiền tệ, 2 số lẻ |
| BASKET_TYPE | string | string | Categorical |
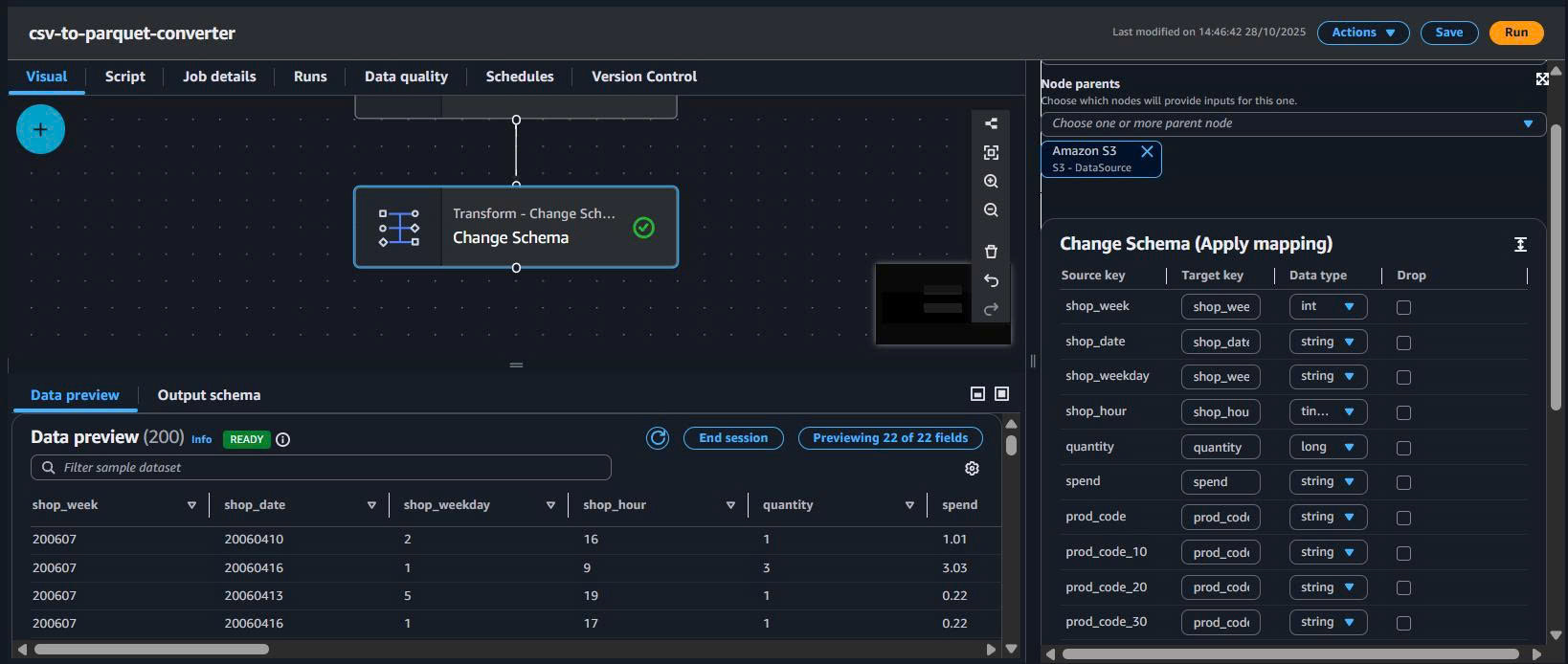
Lợi ích:
- Giảm kích thước file Parquet.
- Tối ưu scan & aggregation.
- Giảm RAM khi đọc dữ liệu.
4.5. Target – ghi Parquet (Snappy) ra silver/
- Thêm node S3 Target.
- Kết nối ApplyMapping → Target.
- Cấu hình:
Data target: S3
Format: Parquet
Compression: Snappy
S3 path: s3://mlops-retail-prediction-dev-842676018087/silver/transactions/
Partition keys: SHOP_WEEK (khuyến nghị)
Minh họa:
– Target config: ../images/s3-data-storage/target-config.png
– Toàn pipeline: ../images/s3-data-storage/04-glue-etl.png
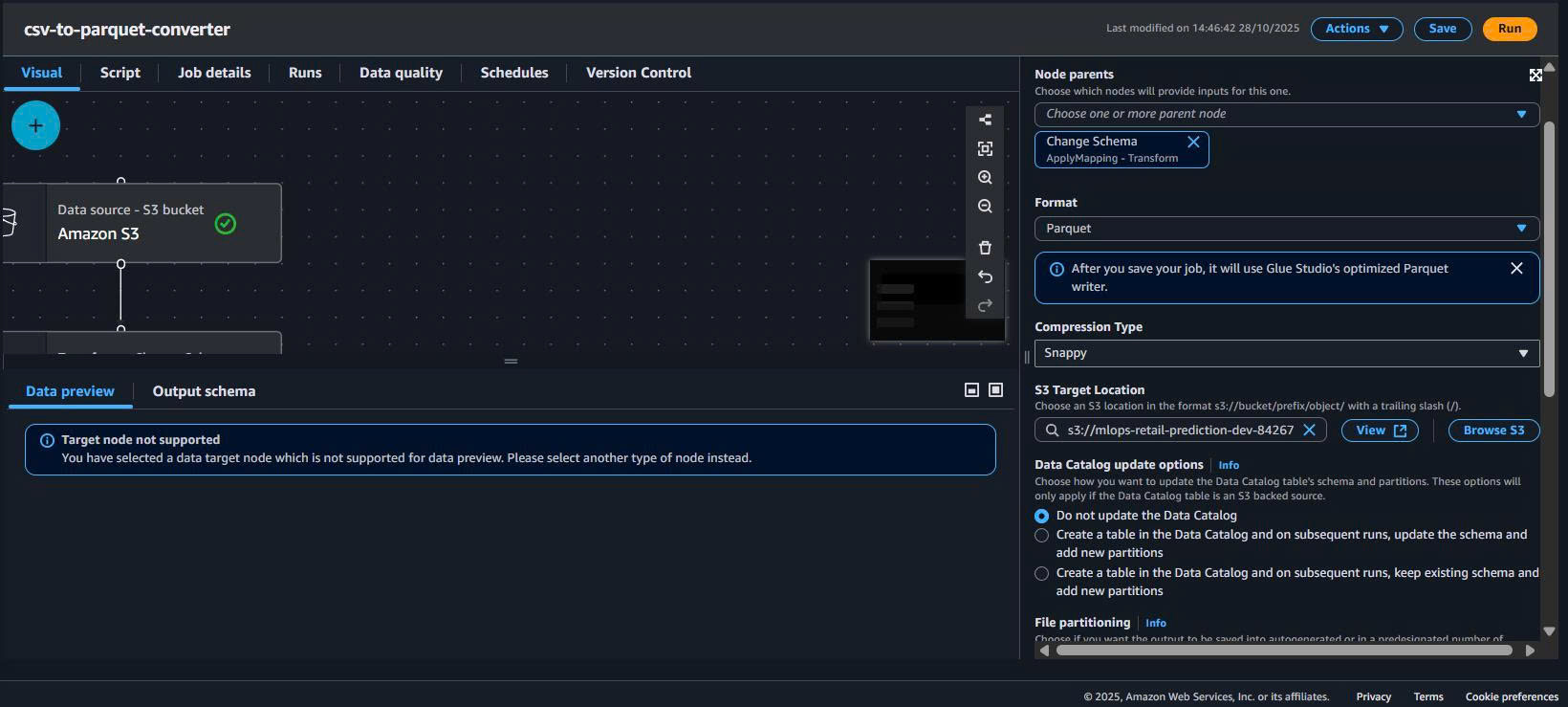
- Save & Run job → theo dõi Job run details → kiểm tra output trong
silver/.
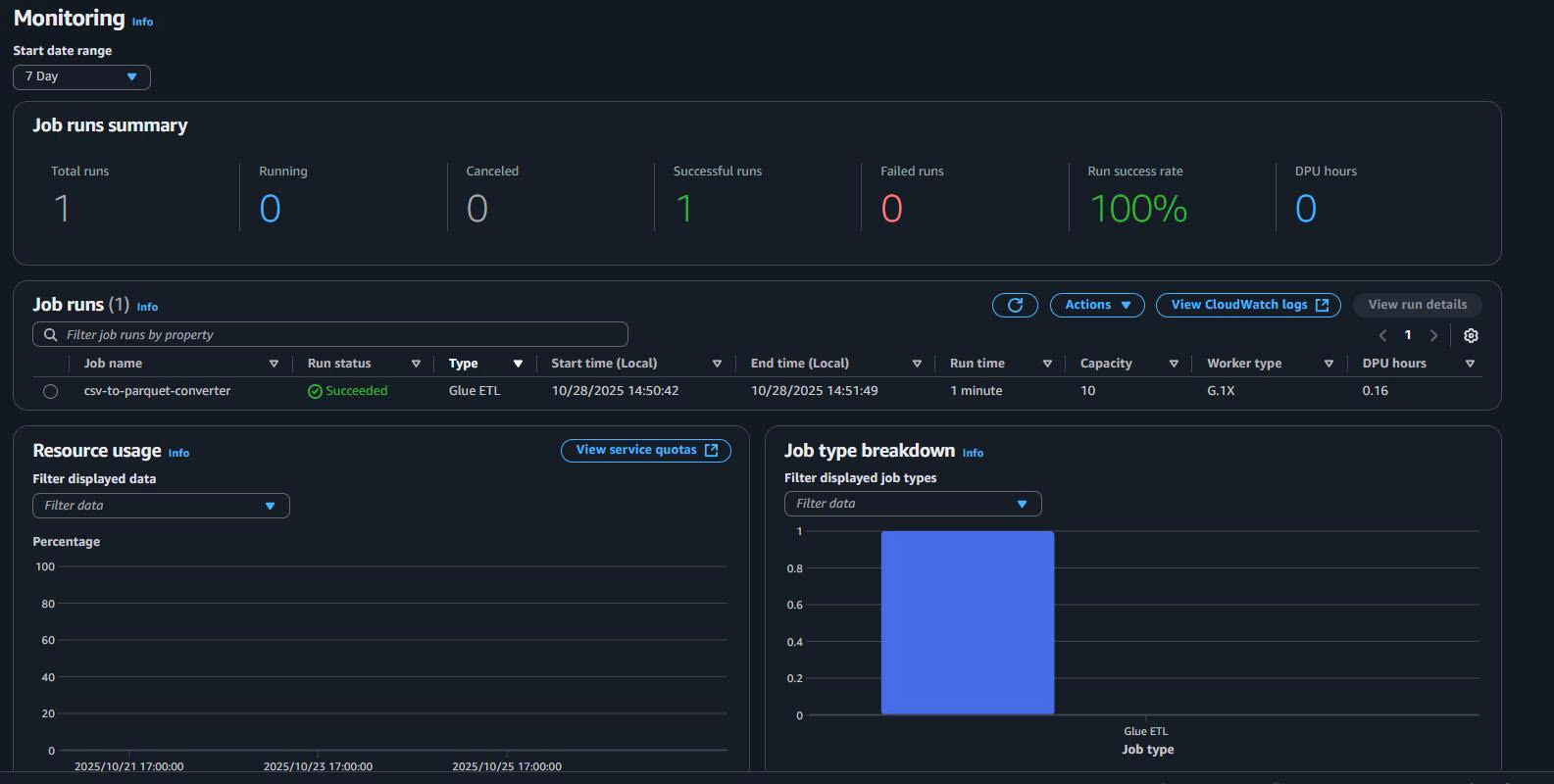
5. Benchmark thực tế trên AWS CloudShell (đọc trực tiếp từ S3)
5.1. Thông tin dataset & cách chạy
-
Chạy trên AWS CloudShell.
-
Đọc trực tiếp:
raw/transactions.csv(~4,593.65 MB, 33,850,823 rows).- 1 file Parquet (~458.45 MB, 33,850,823 rows).
Bạn đã dùng script kiểu:
read_csv_s3(...)để đo đọc CSV.read_parquet_s3(...)để đo đọc Parquet.
Log chi tiết đã hiện trong CloudShell.)
Kết quả đo đọc CSV:

Kết quả đo đọc Parquet:

5.2. Kết quả đo (CloudShell)
CSV – đọc toàn bộ raw/transactions.csv từ S3
5 lần đo:
151.91s, 146.34s, 141.52s, 126.03s, 115.95s
Tính trung bình (xấp xỉ):
- Avg time ≈ 136.35 s
- Size = 4,593.65 MB
- Avg throughput ≈ 33.7 MB/s
- Rows/s ≈ ~248k rows/s
Parquet – đọc 1 file ~458.45 MB từ S3
5 lần đo:
61.37s, 53.65s, 52.51s, 49.66s, 49.55s
Tính trung bình (xấp xỉ):
- Avg time ≈ 53.35 s
- Size = 458.45 MB
- Avg throughput ≈ 8.6 MB/s
- Rows/s ≈ ~635k rows/s
5.3. Bảng so sánh (CloudShell)
| Loại | Size trên S3 | Avg time (s) | Avg throughput (MB/s) | Rows | Rows/s (xấp xỉ) | Relative rows/s |
|---|---|---|---|---|---|---|
| CSV | 4,593.65 MB | 136.35 | 33.7 | 33,850,823 | ~248k | 1× |
| Parquet | 458.45 MB | 53.35 | 8.6 | 33,850,823 | ~635k | ~2.6× |
Giải thích:
- Theo MB/s, CSV có vẻ “nhanh” hơn vì mỗi run xử lý nhiều MB hơn (4.59 GB).
- Nhưng xét số dòng/giây (rows/s), Parquet nhanh hơn ~2.6×, phù hợp cho ETL / training.
Kết luận CloudShell
- Parquet (Snappy) giảm mạnh dung lượng: 4.59 GB → ~0.46 GB.
- Với cùng 33.85M dòng, Parquet xử lý nhanh hơn ~2.6× về rows/s.
6. Benchmark trên máy local (Windows, 16GB RAM)
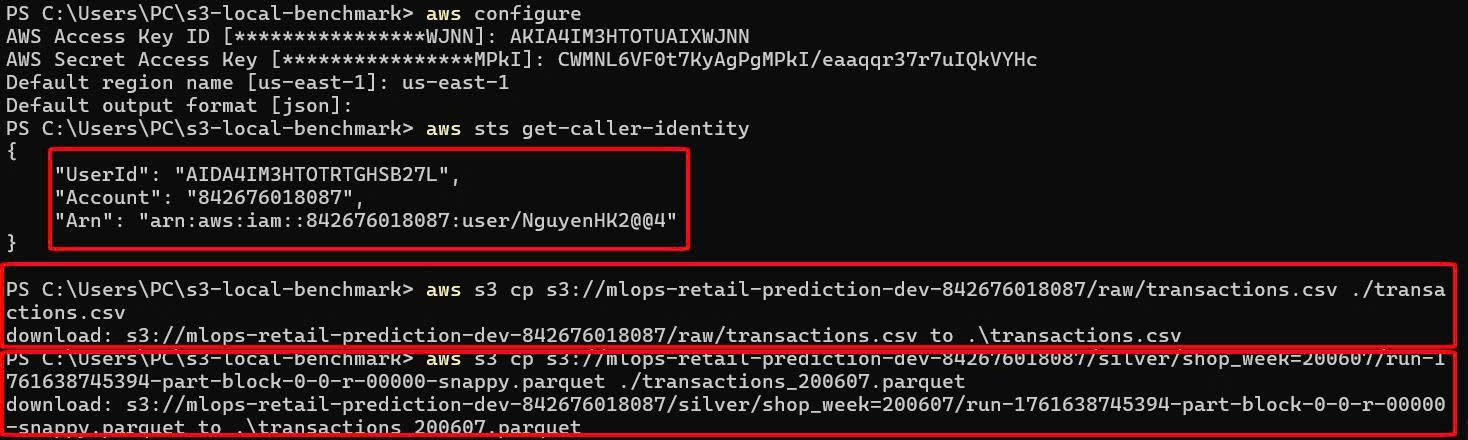
6.1. Chuẩn bị thư mục & tải dữ liệu
Trên Windows:
mkdir s3-local-benchmark
cd s3-local-benchmark
Tải 2 file:
aws s3 cp s3://mlops-retail-prediction-dev-842676018087/raw/transactions.csv ./transactions.csv
aws s3 cp s3://mlops-retail-prediction-dev-842676018087/silver/shop_week=200607/run-1761638745394-part-block-0-0-r-00000-snappy.parquet ./transactions_200607.parquet
6.2. Script benchmark
Tạo file local_benchmark.py:
import time
import os
import pandas as pd
def bench_csv_stream(path: str, runs: int = 3):
print(f"=== Benchmark CSV (streaming): {path} ===")
size_mb = os.path.getsize(path) / (1024 * 1024)
for i in range(1, runs + 1):
t0 = time.time()
rows = 0
# Đọc theo chunks để tránh tràn RAM
for chunk in pd.read_csv(path, chunksize=500_000):
rows += len(chunk)
t1 = time.time()
elapsed = t1 - t0
throughput = size_mb / elapsed
print(f"[local_csv_stream] run={i} time={elapsed:.2f}s, "
f"size={size_mb:.2f} MB, throughput={throughput:.2f} MB/s, rows={rows}")
def bench_parquet_stream(path: str, runs: int = 3):
print(f"
=== Benchmark Parquet (streaming): {path} ===")
size_mb = os.path.getsize(path) / (1024 * 1024)
for i in range(1, runs + 1):
t0 = time.time()
df = pd.read_parquet(path)
rows = len(df)
t1 = time.time()
elapsed = t1 - t0
throughput = size_mb / elapsed
print(f"[local_parquet_stream] run={i} time={elapsed:.2f}s, "
f"size={size_mb:.2f} MB, throughput={throughput:.2f} MB/s, rows={rows}")
if __name__ == "__main__":
bench_csv_stream("transactions.csv", runs=3)
bench_parquet_stream("transactions_200607.parquet", runs=3)
Chạy:
python local_benchmark.py
6.3. Log thực tế
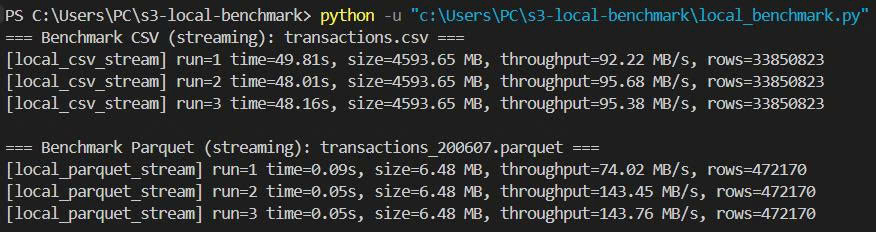
**Nhận xét:**
- CSV full 4.59 GB: vẫn xử lý được nhờ đọc theo chunks, throughput ~90–95 MB/s.
- Parquet (sample 1 tuần, 6.48 MB): thời gian đọc ~0.05–0.09s → latency cực thấp.
- Với nhiều file Parquet nhỏ (partition theo `shop_week`), query theo tuần/tháng sẽ rất nhanh.
7. IAM – Quyền tối thiểu cho Glue Job (tóm tắt)
Tối thiểu cần:
- S3:
s3:GetObjectchoraw/*s3:PutObjectchosilver/*
- Glue:
- Quyền tạo/chạy job, đọc metadata (tùy môi trường).
- CloudWatch Logs: ghi log job.
Ví dụ policy:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": ["s3:GetObject", "s3:PutObject"],
"Resource": [
"arn:aws:s3:::mlops-retail-prediction-dev-842676018087/raw/*",
"arn:aws:s3:::mlops-retail-prediction-dev-842676018087/silver/*"
]
},
{
"Effect": "Allow",
"Action": [
"glue:*",
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents"
],
"Resource": "*"
}
]
}
8. Tổng kết Task 3 – S3 Data Storage
Về kiến trúc:
-
Thiết kế bucket theo chuẩn MLOps:
raw/ → silver/ → gold/ → artifacts/ -
Duy trì raw/ immutable.
-
Chuẩn hóa dữ liệu vào Parquet (Snappy) trong silver/.
Về hiệu năng (từ số đo thực tế của bạn):
-
4.59 GB CSV → ~0.46 GB Parquet cho cùng 33.85M dòng.
-
Trên CloudShell:
- CSV: ~136s, ~248k rows/s.
- Parquet: ~53s, ~635k rows/s → ~2.6× rows/s.
-
Trên máy local (16GB RAM):
- CSV 4.59 GB vẫn xử lý được với chunk 500k rows.
- Parquet sample 1 tuần (~6.48 MB) đọc trong ~0.05–0.09s.
Về cost & vận hành:
- Parquet + Snappy giảm đáng kể dung lượng → giảm tiền S3.
- Intelligent-Tiering giúp tự động hạ tầng lớp lưu trữ cho dữ liệu cũ.
- Glue Visual ETL giúp không cần code nhiều, dễ show trong báo cáo.
9. Clean Up Resources (AWS CLI)
9.1. Xóa tất cả objects trong S3 bucket
# Xóa tất cả files trong bucket
aws s3 rm s3://mlops-retail-prediction-dev-842676018087 --recursive
# Kiểm tra bucket đã trống
aws s3 ls s3://mlops-retail-prediction-dev-842676018087 --recursive
9.2. Xóa S3 bucket
# Xóa bucket (chỉ khi đã trống)
aws s3 rb s3://mlops-retail-prediction-dev-842676018087
# Kiểm tra bucket đã bị xóa
aws s3 ls | grep mlops-retail-prediction-dev
9.3. Xóa Glue Job
# Liệt kê Glue jobs
aws glue get-jobs --query 'Jobs[?contains(Name, `csv-to-parquet`)].Name'
# Xóa Glue job
aws glue delete-job --job-name csv-to-parquet-converter
# Kiểm tra job đã bị xóa
aws glue get-job --job-name csv-to-parquet-converter
9.4. Xóa IAM Role (nếu tạo riêng cho Glue)
# Detach policies khỏi role
aws iam detach-role-policy --role-name GlueETLRole --policy-arn arn:aws:iam::aws:policy/service-role/AWSGlueServiceRole
# Xóa inline policies (nếu có)
aws iam delete-role-policy --role-name GlueETLRole --policy-name S3AccessPolicy
# Xóa role
aws iam delete-role --role-name GlueETLRole
10. Bảng giá S3 Storage (ap-southeast-1)
10.1. Chi phí lưu trữ theo class
| Storage Class | Giá (USD/GB/tháng) | Minimum Duration | Ghi chú |
|---|---|---|---|
| S3 Standard | $0.025 | None | Frequent access |
| S3 Standard-IA | $0.0138 | 30 days | Infrequent access |
| S3 One Zone-IA | $0.011 | 30 days | Single AZ |
| S3 Glacier Instant | $0.005 | 90 days | Archive, instant retrieval |
| S3 Glacier Flexible | $0.0045 | 90 days | Archive, 1-12 hours retrieval |
| S3 Deep Archive | $0.002 | 180 days | Long-term archive, 12+ hours |
10.2. Chi phí requests
| Request Type | Giá (USD/1000 requests) | Ghi chú |
|---|---|---|
| PUT/POST/LIST | $0.0055 | Write operations |
| GET/SELECT | $0.00044 | Read operations |
| Data Transfer OUT | $0.12/GB | First 1GB free/month |
10.3. Ước tính chi phí cho project
Dữ liệu hiện tại:
- Raw CSV: 4.59 GB
- Silver Parquet: 0.46 GB
- Tổng: ~5 GB
Chi phí hàng tháng (S3 Standard):
| Component | Size | Price/GB | Monthly Cost |
|---|---|---|---|
| Raw data (CSV) | 4.59 GB | $0.025 | $0.11 |
| Silver data (Parquet) | 0.46 GB | $0.025 | $0.01 |
| Gold + artifacts | ~0.5 GB | $0.025 | $0.01 |
| Total Storage | ~5.5 GB | $0.14 | |
| Requests (ước tính) | ~1000 req | $0.0055 | $0.006 |
| Grand Total | ≈ $0.15/month |
Với Intelligent Tiering:
- Sau 30 ngày: Raw data chuyển Standard-IA → tiết kiệm ~45%
- Sau 90 ngày: Old artifacts chuyển Glacier → tiết kiệm ~80%
- Ước tính tiết kiệm: ~$0.05-0.08/month
💰 Chi phí Storage tối ưu
- Hiện tại: ~$0.15/month cho 5.5GB
- Với Intelligent Tiering: ~$0.07-0.10/month
- Parquet format: Giảm 90% dung lượng so với CSV
🎯 Task 3 hoàn thành
- Kiến trúc S3 rõ ràng, chuẩn MLOps.
- CSV → Parquet bằng Glue Studio (Visual, có hình minh họa).
- Có benchmark thực tế trên CloudShell và local, có số liệu cụ thể.
- Clean up commands và pricing breakdown chi tiết.
- Dễ trình bày trong báo cáo & demo cho GV.